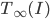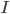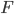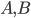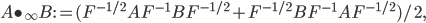A few years back, when I reviewed David Deutsch's The Beginning of Infinity for Physics Today (see also my short note on the review at this blog), I ended up spending a fair amount of time revisiting an area of perennial interest to me: the philosophy of science, and the status of Popper's falsificationist and anti-inductive view of scientific reasoning. I tend to like the view that one should think of scientific reasoning in terms of coherently updating subjective probabilities, which might be thought of as Bayesian in a broad sense. (Broad because it might be more aligned with Richard Jeffrey's point of view, in which any aspect of one's probabilities might be adjusted in light of experience, rather than a more traditional view on which belief change is always and only via conditioning the probabilities of various hypotheses on newly acquired data, with one's subjective probabilities of data given the hypotheses never adjusting.) I thought Deutsch didn't give an adequate treatment of this broadly Bayesian attitude toward scientific reasoning, and wrote:
Less appealing is Deutsch and Popper’s denial of the validity of inductive reasoning; if this involves a denial that evidence can increase the probability of general statements such as scientific laws, it is deeply problematic. To appreciate the nature and proper role of induction, one should also read such Bayesian accounts as Richard Jeffrey’s Subjective Probability: The Real Thing (Cambridge University Press, 2004) and John Earman’s Bayes or Bust? A Critical Examination of Bayesian Confirmation Theory (MIT Press, 1992).
Deutsch and Popper also oppose instrumentalism and physical reductionism but strongly embrace fallibilism. An instrumentalist believes that particular statements or entities are not literally true or real, but primarily useful for deriving predictions about other matters. A reductionist believes that they have explanations couched in the terms of some other subject area, often physics. Fallibilism is the view that our best theories and explanations are or may well be false. Indeed many of the best have already proved not to be strictly true. How then does science progress? Our theories approximate truth, and science replaces falsified theories with ones closer to the truth. As Deutsch puts it, we “advance from misconception to ever better misconception.” How that works is far from settled. This seems to make premature Deutsch’s apparent dismissal of any role for instrumentalist ideas, and his neglect of pragmatist ones, according to which meaning and truth have largely to do with how statements are used and whether they are useful.
Thanks to Brad DeLong I have been reading a very interesting paper from a few years back by Andrew Gelman and Cosma Shalizi, "Philosophy and the practice of Bayesian statistics" that critiques the Bayesian perspective on the philosophy of science from a broadly Popperian---they say "hypothetico-deductive"---point of view, that embraces (as did Popper in his later years) fallibilism (in the sense of the quote from my review above). They are particularly concerned to point out that the increasing use of Bayesian methods in statistical analysis should not necessarily be interpreted as supporting a Bayesian viewpoint on the acquisition of scientific knowledge more generally. That point is well taken; indeed I take it to be similar to my point in this post that the use of classical methods in statistical analysis need not be interpreted as supporting a non-Bayesian viewpoint on the acquisition of knowledge. From this point of view, statistical analysis, whether formally Bayesian or "classical" is an input to further processes of scientific reasoning; the fact that Bayesian or classical methods may be useful at some stage of statistical analysis of the results of some study or experiment does not imply that all evaluation of the issues being investigated must be done by the same methods. While I was most concerned to point out that use of classical methods in data analysis does not invalidate a Bayesian (in the broad sense) point of view toward how the results of that analysis should be integrated with the rest of our knowledge, Gelman and Shalizi's point is the mirror image of this. Neither of these points, of course, is decisive for the "philosophy of science" question of how that broader integration of new experience with knowledge should proceed.
Although it is primarily concerned to argue against construing the use of Bayesian methods in data analysis as supporting a Bayesian view of scientific methods more generally, Gelman and Shalizi's paper does also contain some argument against Bayesian, and more broadly "inductive", accounts of scientific method, and in favor of a broadly Popperian, or what they call "hypothetico-deductive" view. (Note that they distinguish this from the "hypothetico-deductive" account of scientific method which they associate with, for instance, Carl Hempel and others, mostly in the 1950s.)
To some extent, I think this argument may be reaching a point that is often reached when smart people, indeed smart communities of people, discuss, over many years, fundamental issues like this on which they start out with strong differences of opinion: positions become more nuanced on each side, and effectively closer, but each side wants to keep the labels they started with, perhaps in part as a way of wanting to point to the valid or partially valid insights that have come from "their" side of the argument (even if they have come from the other side as well in somewhat different terms), and perhaps also as a way of wanting to avoid admitting having been wrong in "fundamental" ways. For example, one sees insights similar to those in the work of Richard Jeffrey and others from a "broadly Bayesian" perspective, about how belief change isn't always via conditionalization using fixed likelihoods, also arising in the work of the "hypothetico-deductive" camp, where they are used against the simpler "all-conditionalization-all-the-time" Bayesianism. Similarly, probably Popperian ideas played a role in converting some "relatively crude" inductivists to more sophisticated Bayesian or Jefferian approach. (Nelson Goodman's "Fact, Fiction, and Forecast", with its celebrated "paradox of the grue emeralds", probably played this role a generation or two later.) Roughly speaking, the "corroboration" of hypotheses of which Popper speaks, involves not just piling up observations compatible with the hypothesis (a caricature of "inductive support") but rather the passage of stringent tests. In the straight "falsification" view of Popper, these are stringent because there is a possibility they will generate results inconsistent with the hypothesis, thereby "falsifying" it; on the view which takes it as pointing toward a more Bayesian view of things (I believe I once read something by I.J.Good in which he said that this was the main thing to be gotten from Popper), this might be relaxed to the statement that there are outcomes that are very unlikely if the hypothesis is true, thereby having the potential, at least, of leading to a drastic lowering of the posterior probability of the hypothesis (perhaps we can think of this as a softer version of falsification) if observed. The posterior probability given that such an outcome is observed of course does not depend only on the prior probability of the hypothesis and the probability of the data conditional on the hypothesis---it also depends on many other probabilities. So, for instance, one might also want such a test to have the property that "it would be difficult (rather than easy) to get an accordance between data x and H (as strong as the one obtained) if H were false (or specifiably flawed)". The quote is from this post on Popper's "Conjectures and Refutations" by philosopher of science D. G. Mayo, who characterizes it as part of "a modification of Popper". ("The one obtained" refers to an outcome in which the hypothesis is considered to pass the test.) I view the conjunction of these two aspects of a test of a hypothesis or theory as rather Bayesian in spirit. (I do not mean to attribute this view to Mayo.)
I'll focus later---most likely in a follow-up post---on Gelman and Shalizi's direct arguments against inductivism and more broadly Bayesian approaches to scientific methodology and the philosophy of science. First I want to focus on a point that bears on these questions but arises in their discussion of Bayesian data analysis. It is that in actual Bayesian statistical data analysis "the prior distribution is one of the assumptions of the model and does not need to represent the statistician's personal degree of belief in alternative parameter values". They go on to say "the prior is connected to the data, so is potentially testable". It is presumably just this sort of testing that Matt Leifer was referring to when he wrote (commenting on my earlier blog entry on Bayesian methods in statistics)
"What I often hear from statisticians these days is that it is good to use Bayesian methods, but classical methods provide a means to check the veracity of a proposed Bayesian method. I do not quite understand what they mean by this, but I think they are talking at a much more practical level than the abstract subjective vs. frequentist debate in the foundations of probability, which obviously would not countenance such a thing.
The point Gelman and Shalizi are making is that the Bayesian prior being used for data analysis may not capture "the truth", or more loosely, since they are taking into account the strong possibility that no model under consideration is literally true, that it may not adequately capture those aspects of the truth one is interested in---for example, may not be good at predicting things one is interested in. Hence one wants to do some kind of test of whether or not the model is acceptable. This can be based on using the Bayesian posterior distribution as a model to be tested further, typically with classical tests such as "pure significance tests".
As Matthew's comment above might suggest, those of us of more Bayesian tendencies, who might agree that the particular family of priors---and potential posteriors---being used in data analysis (qua "parameter fitting" where perhaps we think of the prior distribution as the (higher-level) "parameter" being fit) might well not "contain the truth", might be able to take these tests of the model, even if done using some classical statistic, as fodder for further, if perhaps less formal, Bayesian/Jeffreysian reasoning about what hypotheses are likely to do a good job of predicting what is of interest.
One of the most interesting things about Gelman and Shalizi's paper is that they are thinking about how to deal with "fallibilism" (Popper's term?), in particular, inference about hypotheses that are literally false but useful. This is very much in line with recent discussion at various blogs of the importance of models in economics, where it is clear that the models are so oversimplified as to be literally false, but nonetheless they may prove predictively useful. (The situation is complicated, however, by the fact that the link to prediction may also be relatively loose in economics; but presumably it is intended to be there somehow.) It is not very clear how Popperian "falsificationism" is supposed to adapt to the fact that most of the hypotheses that are up for falsification are already known to be false. Probably I should go back and see what Popper had to say on that score, later in his career when he had embraced fallibilism. (I do recall that he tried introducing a notion of "verisimilitude", i.e. some kind of closeness to the truth, and that the consensus seems to have been---as Gelman and Shalizi point out in a footnote---that this wasn't very successful.) It seems to that a Bayesian might want to say one is reasoning about the probability of statements like "the model is a good predictor of X in circumstances Y", " the model does a good job capturing how W relates to Z" , and so forth. It is perhaps statements like these that are really being tested when one does the " pure significance tests" advocated by Gelman and Shalizi when they write things like "In designing a good test for model checking, we are interested in finding particular errors which, if present, would mess up particular inferences, and devise a test statistic which is sensitive to this sort of mis-specification."
As I said above, I hope to take up Gelman and Shalizi's more direct arguments (in the cited paper) against "inductivism" (some of which I may agree with) and Bayesianism sensu lato as scientific methodology in a later post. I do think their point that the increasing use of Bayesian analysis in actual statistical practice, such as estimation of models by calculating a posterior distribution over model parameters beginning with some prior, via formal Bayesian conditioning, does not necessarily tell in favor of a Bayesian account of scientific reasoning generally, is important. In fact this point is important for those who do hold such a loosely Bayesian view of scientific reasoning: most of us do not wish to get stuck with interpreting such priors as the full prior input to the scientific reasoning process. There is always implicit the possibility that such a definite specification is wrong, or, when it is already known to be wrong but thought to be potentially useful for some purposes nonetheless, "too wrong to be useful for those purposes".