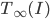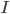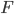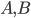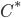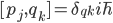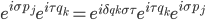The title of this post is also the title of my most recent paper on the arXiv, from 2019, with Joachim Hilgert of the University of Paderborn. The published version is titled Spectral Properties of Convex Bodies, Journal of Lie Theory 30 (2020) 315-355.
Here's a preprint version of the J Lie Theory article:
Compared to the arXiv version, the J Lie Theory version (and the above-linked preprint) has less detail about the background results by other authors (mainly Jiri Dadok's theory of polar representations of compact Lie groups, and the Madden-Robertson theory of regular convex bodies) which we use, and a bit more detail in the proof of our main result. It also has a more extensive discussion of infinite-dimensional Jordan algebraic systems, in the context of discussion of ways in which the Jordan algebraic systems can be narrowed down to the complex quantum ones. I like the title of the arXiv version better, since it states the main result of the paper, but Joachim was scheduled to give a talk at the celebration of Jimmie Lawson's 75th birthday in 2018, while we were writing up the main result, so he gave a talk on our work titled Spectral Properties…, and we decided to publish the paper in the proceedings, which are a special issue of J Lie Theory, so it ended up with the same title as the talk.
Here are slides from a talk on the result I gave to an audience of mathematicians and mathematical physicists:
MadridOperatorAlgebras2019Although the paper's main theorem is a result in pure mathematics, and, I think, interesting even purely from that point of view, it is also a result in the generalized probabilistic theories (GPT) framework for formulating physical theories from a very general point of view, which describes physical systems in terms of the probabilities of the various results of all possible ways of observing (we often say "measuring") those systems. The state in which a system has been prepared (whether by an experimenter or by some natural process) is taken to be defined by specifying these probabilities of measurement-results, and it is then very natural to take the set of all possible states in which a system can be prepared to be a compact convex set. Such sets are usually taken to live in some real affine space, for instance the three-dimensional one of familiar Euclidean geometry, which may be taken to host the qubit, whose state space is a solid ball, sometimes called the Bloch ball. In this framework, measurement outcomes are associated with affine functionals on the set taking real values---in fact, values between 0 and 1 --- probabilities, and measurements are associated with lists of such functionals, which add up to the unit functional---the constant functional taking the value 1 on all states of the system. (This ensures that whatever state of the system is prepared, the probabilities of outcomes of a measurement add up to 1.) This allows an extremely wide variety of convex sets as state spaces, most of which are neither the state spaces of quantum systems nor classical systems. An important part of the research program of those of us who spend some of our time working in the GPT framework is to characterize the state spaces of quantum systems by giving mathematically natural axioms, or axioms concerning the physical properties exhibited by, or the information-processing protocols we can implement using, such systems, such that all systems having these properties are quantum systems. To take just a few examples of the type of properties we might ask about: can we clone states of such systems? Do we have what Schroedinger called "steering" using entangled states of a pair of such systems? Can we define a notion of entropy in a way similar to the way we define the von Neumann entropy of a quantum system, and if so, are there thermodynamic protocols or processes similar to those possible with quantum systems, in which the entropy plays a similar role? Are there analogues of the spectral theorem for quantum states (density matrices), of the projection postulate of quantum theory, of the plethora of invertible transformations of the state space that are described, in the quantum case, by unitary operators? We often limit ourselves (as Joachim and I did in our paper) to finite-dimensional GPT systems to make the mathematics easier while still allowing most of the relevant conceptual points to become clear.
This paper with Joachim builds on work by me, Markus Mueller and Cozmin Ududec, who showed that three principles characterize irreducible finite-dimensional Jordan-algebraic systems (plus finite-dimensional classical state spaces). Since these systems were shown (by Jordan, von Neumann, and Wigner in the 1930s, shortly after Jordan defined the algebras named after him) to be just the finite-dimensional quantum systems over the real, complex, and quaternionic numbers, plus systems whose state space is a ball (of any finite dimension), plus three-dimensional quantum theory over the octonions (associated with the so-called exceptional Jordan algebra), this already gets us very close to a characterization of the usual complex quantum state space (of density matrices) and the associated measurement theory described by positive operators. The principles are (1) A generalized spectral decomposition: every state is a convex combination of perfectly distinguishable pure states, (2) Strong Symmetry: every set of perfectly distinguishable pure states may be taken to any other such set (of the same size) by a symmetry of the state space, and (3) that there is no irreducible three (or more) path interference. Joachim and I characterized the same class of systems using only (1) and (2). In order for you to understand these properties, I need to explain some terms used in them: pure states are defined as states that cannot be viewed as convex combinations of any other states---that is, there is no "noise" involved in their preparation---they are sometimes called "states of maximal information". The states in a given list of states are "perfectly distinguishable" from each other if, when we are guaranteed that the state of a system is one of those in the list, there is a single measurement that can tell us which state it is. The measurement that does the distinguishing may, of course, depend on which list it is. Indeed one can take it as a definition of classical system, at least in this finite-dimensional context, that there is a single measurement that is capable of distinguishing the states in any list of distinct pure states of the system.
If one wants to narrow things down further from the Jordan-algebraic systems to the complex quantum systems, there are known principles that will do it: for instance, energy observability (from the Barnum, Mueller, Ududec paper linked above, although it should be noted that it's closely related to concepts of Alfsen and Shultz ("dynamical correspondence") and of Connes ("orientation")): that the generators of continuous symmetries of the state space are also observables, and are conserved by the dynamics that they generate, a requirement very reminiscent of Noether's theorem on conserved generators of symmetries. Mathematically speaking, we formulate this as a requirement that the Lie algebra of the symmetry group of the state space embeds, injectively and linearly, into the space of observables (which we take to be the ambient real vector space spanned by the measurement outcomes) of the system, in such a way that the embedded image of a Lie algebra generator is conserved by the dynamics it generates. In the quantum case, this is just the fact that the Lie algebra su(n) of an n-dimensional quantum system's symmetry group is the real vector space of anti-Hermitian matrices, which embeds linearly (over the reals) and injectively into the Hermitian matrices (indeed, bijectively onto the traceless Hermitian matrices), which are of course the observables of a finite-dimensional quantum system. This embedding is so familiar to physicists that they usually just consider the generators of the symmetry group to be Hermitian matrices ("Hamiltonians"), and map them back to the antiHermitian generators by considering multiplication by i (that's the square root of -1) as part of the "generation" of unitary evolution. This is discussed in the arXiv version, but the Journal of Lie Theory version discusses it more extensively, and along the way indicates some results on infinite-dimensional Jordan algebraic systems since Alfsen and Shultz, and Connes, worked in frameworks allowing some infinite-dimensional systems. See also John Baez' excellent recent paper, Getting to the Bottom of Noether's Theorem. One can also narrow things down to complex quantum systems by requiring that systems compose in a "tomographically local" way, which means that there is a notion of composite system, made up of two distinct systems, such that all states of the composite system, even the entangled ones (a notion which makes sense in this general probabilistic context, not only in quantum theory), are determined by the probabilities they give to pairs of local meausurement outcomes (i.e. the way in which they correlate (or fail to correlate) these outcomes).